Proving architecture
Focusing specifically on the proving phase of the recursion process; it is a process that starts with proofs of batches (these are sequenced batches of transact
Focusing specifically on the proving phase of the recursion process; it is a process that starts with proofs of batches (these are sequenced batches of transactions) and culminates in a ready-to-be-published validity proof, which is a SNARK proof.
There are five intermediate stages to achieving this; the Compression stage, the Normalization stage, the Aggregation stage, the Final stage and the SNARK stage.
An overview of the overall process can be seen in the below figure.
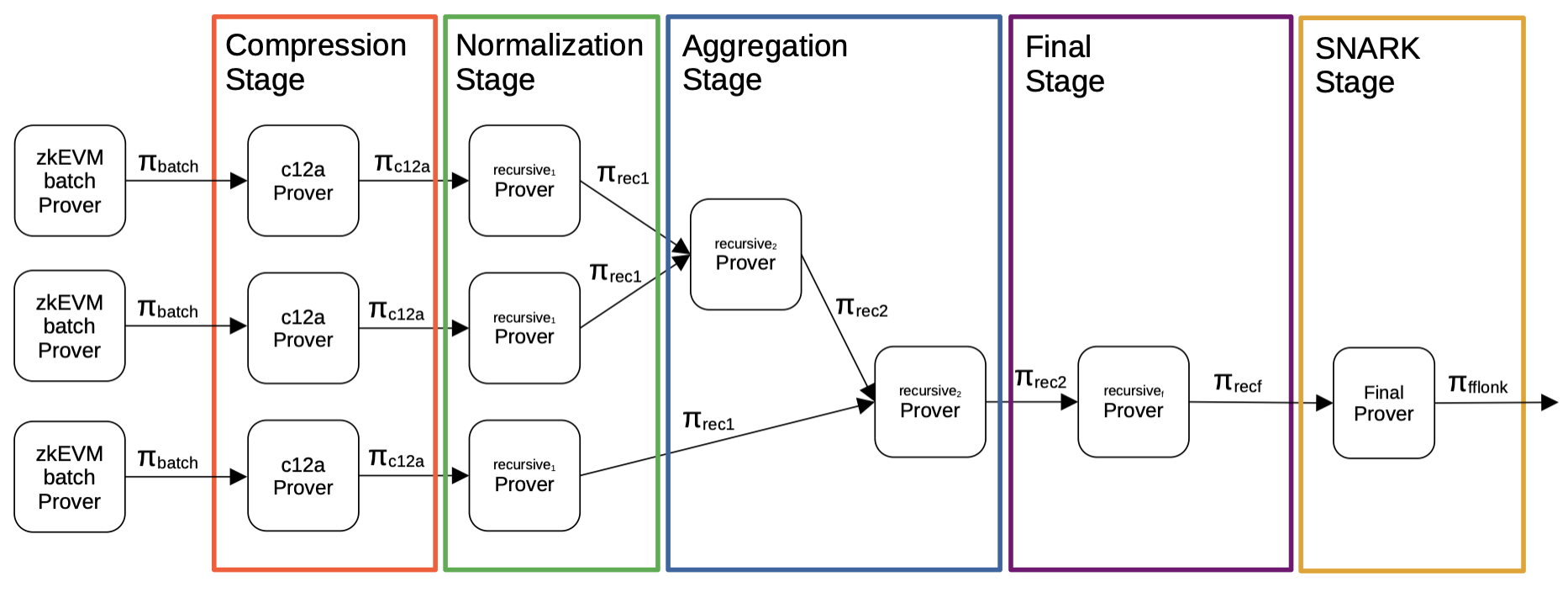
Compression stage
Recall that the first STARK, in the sequence of Recursive provers seen in the Proving phase subsection of the Recursion section, generates a big proof because of its many polynomials, and its attached FRI uses a low blow-up factor.
Henceforth, in each proof of batches, a compression stage is invoked, aiming at reducing the number of polynomials used. This allows the blow-up factor to be augmented, and thus reduce the proof size.
A component called the is utilized in this stage which takes a batch proof as input and outputs a 'compressed' proof, denoted by in the above figure.
Normalization stage
Following completion of the compression stage, is the normalization stage.
Each output of the is taken as an input to the circuit. Outputs of this circuit are referred to as -type proofs.
It is in the next stage, called the Aggregation stage, which is in charge of joining several batch proofs into a single proof that validates each of the single input proofs all at once.
The way to proceed is to construct a binary tree of proofs, where a pair of proofs is proved one pair at a time.
However, since the aggregation of two proofs requires the constant root of the previous circuits, through a public input coming from the previous circuit, the Normalization stage is basically created for this very purpose. The stage is in charge of transforming the obtained verifier circuit, that validates the proof, into a circuit that makes the constant root public to the next circuit.
This step allows each aggregator verifier and the normalization verifier to be exactly the same, permitting successful aggregation via recursion.
Aggregation stage
Once the normalization step has been completed, the next stage is the aggregation of proofs (i.e., normalized proofs).
In this stage, two normalized proofs are joined together by a component.
In order to achieve this, a circuit capable of aggregating two verifiers is created, call it the circuit. Its outputs are proofs of the -type. This circuit is repeatedly applied to pairs of proofs until there are no more normalized proofs to be aggregated.
However, as observed in the figure above, the inputs to the can be proofs of either the -type or the -type.
This allows us to aggregate a pair of -type proofs, or a pair of -type proofs, or even a combination of a -type proof and a -type proof.
Final stage
The final stage is the very last STARK step during the recursion process, and it is in charge of verifying a proof over a completely different finite field, the one defined by the elliptic curve.
More specifically, the hash used in generating the transcript works over the field of the elliptic curve. Hence, all the challenges (and so, all polynomials) belong to this new field.
The reason for the change to the elliptic curve is because a SNARK proof, which works over this type of elliptic curves, is to be generated in the next step of the process.
This step is very much similar to the circuit. It instantiates a verifier circuit for except that, in this case, constant roots should be provided (a constant for each of the proofs aggregated in the former step).
SNARK stage
The last step of the whole process is called the SNARK stage, and its purpose is to produce a proof which validates the previous proof.
In fact, can be replaced with any other SNARKs. One alternative SNARK which was previously used is , which requires a trusted setup for every new circuit.
A SNARK is chosen to replace a STARK with the aim to reduce both verification complexity and proof size. SNARKs, unlike STARK proofs, have constant complexity.
The proof gets published on-chain as the validity proof. The verifier smart contract living on the L1 verifies the validity proof.
Remark on inputs
All public inputs used throughout the entire recursion procedure get hashed together, and the resulting digest forms the public input to the SNARK circuit.
The set of all public inputs is listed below.
oldStateRootoldAccInputHasholdBatchNumchainIdmidStateRootmidAccInputHashmidBatchNumnewStateRootnewAccInputHashlocalExitRootnewBatchNum
Last updated on
Recursion sub-process
This document provides a deep dive into the sub-processes S2C and C2S of the Recursion of Proofs. ## Setup S2C Recall that S2C denotes the process of converting
CIRCOM in zkProver
Although CIRCOM is mainly used to convert a STARK proof into its respective Arithmetic circuit, it is implemented in varied ways within the zkProver, specifical